THE TOWER OF BABEL
or the problem of displaying scripts on the Internet and the Unicode solution.
| HOME | THE BEGINNING | UNICODE | REFERENCES |
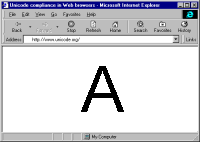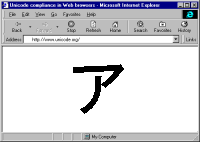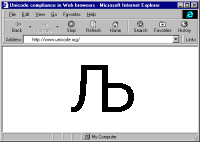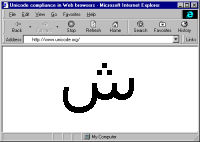
... Come, let us go down, and there confuse their language, that they may not understand one another's speech." So the Lord scattered them abroad from there over the face of all the earth, and they left off building the city. (Genesis 11:7-8)
SCRIPTS
Script is a visual representation of spoken language, where individual characters represent a sound or an idea. In his book about writing systems, Coulmas (1991) divides all scripts in two basic groups – symbolic (pleremic) and phonetic (cenemic). Roughly, the Chinese script (kanji) would be example of pleremic script, while the alphabet would be of cenemic scripts. However, most of the scripts are variations of both – the kanji could stand for the sound and phonetic script could use more than one character to represent a sound.
The history of scripts is usually presented as a development from the primitive pictograms of hieroglyphs toward more symbolic cuneiform syllabic script which ultimately evolved into sophisticated alphabet script where sound (phoneme) is paired with character (morpheme). The inference is that the alphabet is the paramount ideal. Some authors directly relate success of western civilization to the adoption of the alphabetic script, notably through implementation of movable type and modular thinking. As with misinterpretation of the concept of evolution in the infamous image of stages of evolution from monkey to the Homo sapiens (to great annoyance of Darwin himself and generation of evolutionist after him) use of the ideograms or alphabet have nothing to do with intellectual or civilization development of individual culture. English and American persistence in the use of inches and cups as the dominant measuring system does not say anything about the ability of its citizens to perform quality mathematics.
 |
Spoof on Victorian interpretation of Darwin’s theory of evolution. This Greek web site is an interesting example of use of the Unicode encoding in multi-script environment. |
The visual and structural systems of scripts vary because languages vary. A script is adapted to a particular language and is a good representation of the language–its sounds, grammar and syntax. The language spoken in Summer was syllabic. The words were formed from distinct and limited number of syllables and therefore their characters represent syllables. Semitic languages – Phoenician, Hebrew, or Arabic – have a unique pattern of stems consisting of consonantal roots for which the phonetic alphabet was more suitable, but they do not need characters for vowels. The Greek language belongs to the Indo-European language group with vowel clusters that required addition of vowel characters.
The size of the alphabet, the number of characters used to represent the language, or the forms the characters take, have nothing to with the “quality” of the writing system. As Coulmas (1991) points out: “the relative economy of sign inventory is only one characteristic feature distinguishing writing systems of different structural levels which by itself cannot serve as a measure of goodness” (p. 52). Ideograms have unique graphic quality that enables rapid understanding and disassociation from specific language. And contrary to the popular belief, almost none of the pleremic scripts are strictly ideographic. They all, including Egyptian hieroglyphs (Coulmas 1991, p. 50) use combination of symbols that represent ideas as well as sounds to convey the message.
In the Mediterranean basin, almost all of the languages use alphabet based scripts. The Phoenician alphabet evolved into the Greek, Hebrew, and Arabic scripts. The Greek script becomes the foundation of the Latin as well as the Cyrillic scripts, showing how the same base can develop in two distinctly different visual forms. Some other alphabets of the region, like Armenian or Georgian, created their scripts form scratch, i.e., did not evolve from logogram -- as the Hebrew letter א (‘aleph) evolved from the pictogram of an ox. Although the shape of the letters are arbitrary, they follow phonetic principle representing each phonemes with the character.
|
'aleph, the ox, began as the image of an ox's head. It represents a glottal stop before a vowel. The Greeks, needing vowel symbols, used it for alpha (A). The Romans used it as A. |
|
| The original form and sound associated with the morpheme A. Full table and more about ORIGINS OF ALPHABET on the web site developed by George Boeree, Shippensburg University PA. | ||
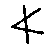
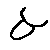
Every language is written in some customary direction: left to right (Latin as well as Cyrillic), right to left (Hebrew and Arabic) or top down (Chinese). In some scripts, like Arabic, the text is written from right to left, but numbers are written from left to right and therefore are considered bidirectional (BiDi).
In the process of modification of the ASCII character encoding to the local scripts, different languages encoded their characters based on the locally standardized typewriter keyboard. One country uses one character-mapping standard for their alphabet and another country uses the same for their alphabet, and the display became a serious problem, especially on the Internet. Croatian Latin keyboards used the YUSCII encoding, where the sign for [ was replaced with Š, the tilde key was used for character ć, end so forth. Therefore, web pages using YUSCII, displayed in the browsers able to display only ASCII, would display tildes and carons instead ČŽŠs. In addition, the applications using ASCII will put all special signs on the end of the sorted list although according the alphabetic order using Croatian alphabet Ć come after C and before Č. The uniqueness of the Unicode encoding is that prevents this code borrowings and ensure that, provided that computer appropriate glyph files, every text would display in the same way and that every coding sequence searched will return the character it specified.
The users of non-English Latin scripts tried to control the chaos with the establishment of an standard and unique mapping of Latin characters across the languages. First with ANSI, then with ISO/IEC 646. The latest standard ISO-8859 is devised to work together with 16-bit Unicode chart sets. Today almost all web browsers support ISO standards and browsing through virtual Europe becomes a pleasure. Almost everybody who has the ability and knowledge to publish on the Web uses modern standards and encoding schemes. In this way, standardization helped the variation of the scripts on the Internet. While before, anybody who could was transcribing in ASCII Latin, but now everybody can indulge in full use and display of their scripts and special characters.
It would be nice if the matter of encoding would solve all multi-lingual problems. Most of the non-English Latin alphabet writers become used to a stripped down form of their language, writing München as Muenchen or even more often as Munchen. The people who have enough knowledge about HTML customarily wrote header information with keywords in original and ASCII script (like in meta header in web site Ћирилица) in order to enable search returns for users without knowledge or ability to type in original scripts.
Some languages could be easily written in different scripts. Serbian, which is customarily written in Cyrillic, could be transliterated in Croatian Latin alphabet without losing any of the information or even the pronunciation. The languages are very similar and the use of different scripts has more historic than linguistic reasons. However, the Serbian grammar is more strict in its application of the phonetic rule and require that all foreign names are transcribed in Cyrillic according the local pronunciation. Therefore, John Cusack become Џон Кјусак that would transliterate back in Croatian Latin as Đon Kjusak. The term entered in that form will not bring any returns in an Internet search.
However, the dream of librarians of sorting multi-lingual multi-script entries by some egalitarian principle across scripts (Aliprand in Byrum 1998, p. 106) could not be solved even if encoded in Unicode, because the sorting order is associated with a language. As Tull (2002) showed with the example of Chinese (kanji) characters: in China they are sorted by the number of strokes forming the character but in Japan characters are sorted “by the pronunciation of the Japanese characters in gojuon order” (p. 184). In Korea, kanji characters are customarily sorted by number of strokes like in China, but the Korean script follows the Hangul alphabet order. It is definitely possible to sort entries in some (numerical) order, however it would seem arbitrary to the end user even if he were familiar with different scripts and languages. As Agenbroad (Byrum 1998) pointed out people have no concept of order between scripts -- would a Greek precede or follow an Arabic, or a Chinese character (p. 115)?
Explore the beauty of different languages and scripts:
Armenian language and script
About languages and scripts
Serbian language and script
This web site was developed for the Special Study class
of SJSU School of Library and Information Science
Text and design by Vlasta Radan.
Last update May 16, 2006.